Posts

Intractable inference problems
Evidence Lower Bound
Intractable Inference
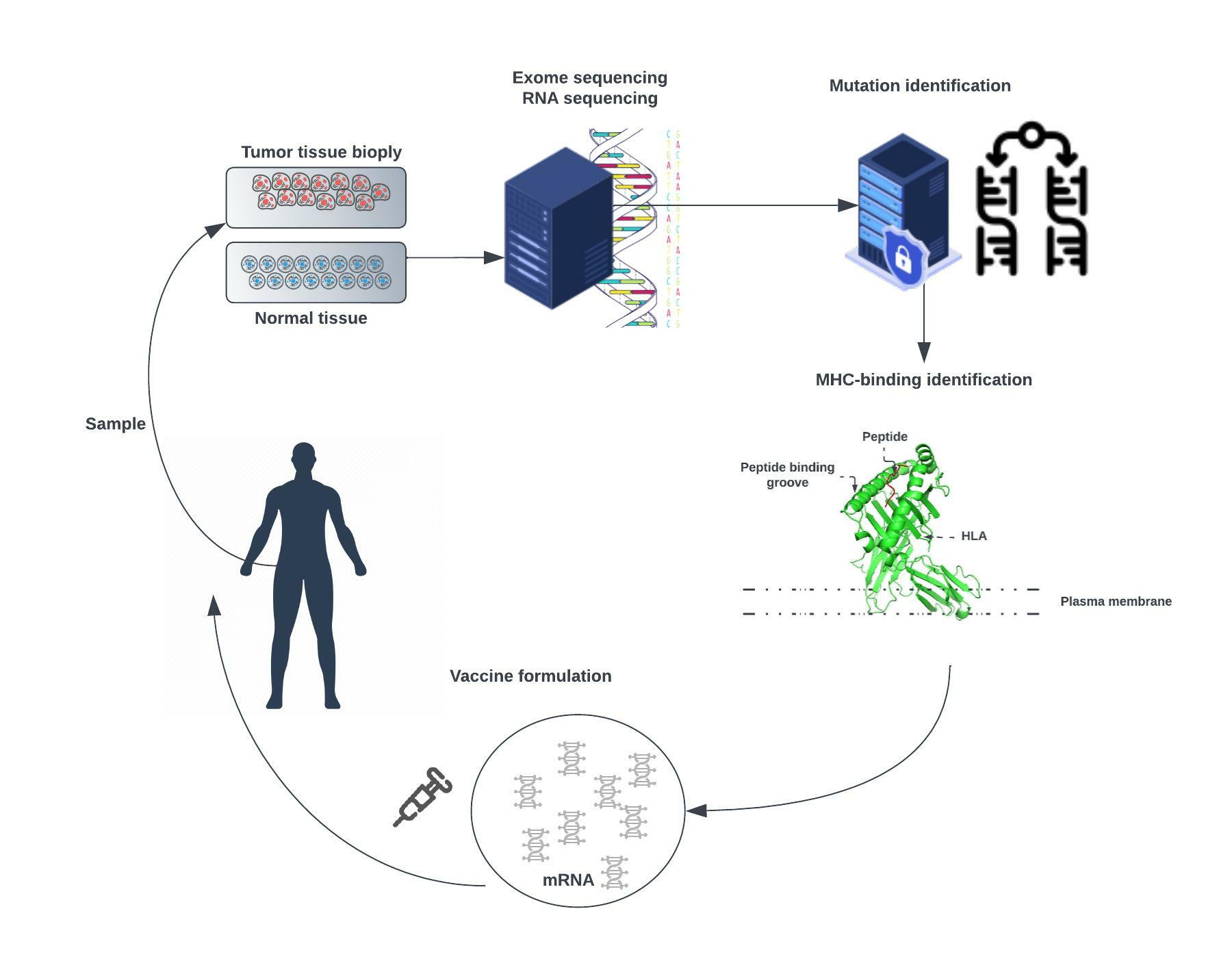
Publication:In silico Antibody-Peptide Epitope prediction for Personalized cancer therapy
Personalized therapy
networks
machine learning

Are tumors patient specific
Personalized therapy
networks
machine learning
deep learning
Policy gradient methods
Reinforcement Learning
Reinforce
Policy gradient methods
Policy approximations
No matching items